
SEMICONDUCTOR SCHOOL
정식 오픈 준비 중 run by EdgeChipLab
실전형 반도체 교육 플랫폼
- 트랜지스터부터 RISC-V CPU, AI NPU, Transformer Attention Engine, AI SoC까지, 직접 설계·구현·검증하는 풀스택 반도체 설계 교육을 제공합니다.
- AI 반도체 기업의 신입 설계 엔지니어가 현업 적응 과정에서 학습하는 핵심 설계 역량을 체계적으로 익힐 수 있도록 구성하였습니다.
SECTION 01. VISION
Transistors to CPU/NPUEdgeChipLab은 반도체 소자의 물리적 이해에서 출발하여, 독자적인 RISC-V CPU 코어 설계와 자체 개발 AI NPU 가속기 구현에 이르는 전 과정을 관통하는 글로벌 지식 공유 플랫폼을 지향합니다.단편적인 이론 습득이나 단기 연구과제 수준의 교육과는 차별화됩니다. 설계한 제품의 하드웨어 구현을 통해 FPGA 실리콘 위에서 동작하는 실전적 결과물을 완성합니다.특히, 인공신경망 아키텍처 설계의 무결성을 검증하는 Bit-True Verification (Python Reference Model과 Verilog RTL 간의 비트 단위 일치 검증) 을 우선 가치로 둡니다. 이를 통해 라이선스 제약이 없는 독자 설계한 RISC-V 프로세서(Edge-RISC)는 소프트웨어 검증 모델과 동일한 연산 결과를 출력하는 고신뢰성 AI NPU를 제어하며 Edge AI 플랫폼을 실현합니다.더 나아가 EdgeChipLab이 추구하는 가치는 CPU나 NPU 하나를 구현하는 것에 머물지 않습니다. 현대의 프로세서, AI 가속기, 센서 인터페이스, 디스플레이 제어기, 통신 모듈, 메모리 시스템, 버스 아키텍처는 다양한 설계 블록이 계층적으로 결합되어 형성된 결과물입니다.우리는 AI 반도체 시스템 설계의 본질을 "검증된 블록의 조립" 이라는 관점에서 접근합니다. 하나의 논리 게이트는 조합논리 회로를 형성하고, 조합논리는 FSM과 데이터패스를 구성하며, 이들은 다시 파이프라인 CPU와 메모리 시스템으로 확장됩니다. 이후 MMIO 기반 시스템 아키텍처를 통해 Camera, OLED, GPS, AI NPU와 같은 독립적인 기능 모듈을 연결하고, 최종적으로 하나의 Edge AI SoC를 구축합니다.이 과정은 정교하며 거대한 레고 성을 쌓아 올리는 과정과 유사합니다. 작은 블록 하나를 직접 만들고, 기능을 검증하고, 다음 블록과 연결하는 과정을 반복합니다. 각각의 블록이 정확하게 동작하고 인터페이스가 명확하게 정의되어 있다면, 상위 계층 역시 예측 가능한 방식으로 동작합니다. 복잡한 시스템은 결코 우연히 만들어지지 않으며, 수많은 검증된 설계 블록들의 축적을 통해 완성된다는 것을 수강생은 직접 경험합니다.EdgeChipLab은 이러한 철학을 바탕으로 모든 설계 계층을 화이트박스(White-box) 형태로 공개합니다. 수강생은 완성된 블랙박스 IP를 사용하는 사용자가 아니라, CPU를 설계하고, NPU를 구현하고, 주변장치를 통합하며, 궁극적으로 자신만의 AI SoC를 구축할 수 있는 시스템 아키텍트 공급자로 성장하게 됩니다.작은 블록 하나가 시스템이 되고, 시스템이 플랫폼이 되며, 결국 나만의 고유한 AI SoC가 완성되는 경험. 그것이 EdgeChipLab이 추구하는 반도체 설계 교육의 본질입니다.
SECTION 02. WHY EdgeChipLab (6가지 핵심차별점)
01. 국제 검증된 자체 RISC-V CPU 코어 — "외부 IP 0%"
상용 ARM 코어나 공개된 IP를 사용하지 않습니다.
EdgeChipLab은 표준 RV32I Instruction Set을 100% 자체 구현하였으며, RISC-V 국제 재단 공식 컴플라이언스 프레임워크(ACT) 검증을 Pass하였습니다 (2026년 5월).
→ 수강생은 "블랙박스 위에서 코딩"하지 않고, 본인의 투명한 코어 위에서 학습합니다.
02. Bit-True Verification — Python ↔ Verilog RTL "1비트 오차 없음"
산업 현장에서도 가장 까다로운 검증 방법론을 교육 표준으로 삼습니다.
Python 레퍼런스 모델과 Verilog RTL의 인공신경망 연산 결과가 단 1비트도 어긋나지 않는 무결성을 NPU 설계에 적용합니다. (MNIST 100 sample set PASS)
→ "동작하는 것 같다"가 아니라 "수학적으로 동일하다"를 체험합니다.
03. Transistor → AI SoC → Transformer까지 단일 로드맵
소자 물리부터 CPU, RTOS, 멀티코어, NPU, AI SoC, Transformer Attention Processor까지 모든 과정을 하나의 교육 체계 안에서 학습합니다.
→ 반도체 설계 전 과정을 처음부터 끝까지 연결하는 One-Stop 설계 로드맵을 제공합니다.
04. 실리콘 위에서 검증된 결과물 — "시뮬레이션이 아닌 실물 동작"
대부분의 교육은 시뮬레이션 파형에서 끝납니다. EdgeChipLab은 RV32I CPU, AI NPU, AI Edge SoC, Transformer Attention Processor를 FPGA 실리콘 위에서 직접 동작시키고 검증합니다.
→ "내가 만든 칩이 동작하는 영상"을 포트폴리오로 보유할 수 있습니다.
05. 소스코드 공개 + 강남 1:1 실물 멘토링
CPU RTL, NPU RTL, Python Golden Model, Testbench, C Firmware까지 모두 공개합니다.
학생은 블랙박스 IP를 사용하는 것이 아니라 직접 수정·확장·재설계할 수 있습니다.
→ 사용자가 아닌 설계자를 양성합니다.
06. 국제 검증 자산 기반 교육
RISC-V ACT Pass CPU
Amazon 출판
FPGA 실증 결과
공개 GitHub (https://github.com/estlit)
Bit-True Verification
→ 실제 검증된 자산을 기반으로 학습합니다.
SECTION 03. PROVEN PORTFOLIO
EdgeChipLab의 모든 핵심 결과물은 외부 IP나 라이선스에 의존하지 않고 기초부터 자체 개발한 기술 자산입니다. 우리의 포트폴리오는 학술적 엄밀성과 글로벌 출판 시장, 그리고 실제 실리콘(FPGA) 환경에서의 교차 검증을 통해 아키텍처의 실 동작을 입증하였습니다.
▶ Academic & Curriculum Authority
- 인서울 반도체공학과 교수의 풍부하고 차별화된 실기/실무 중심 교과과정 제공
- 학습자의 역량에 따른 수준별(Level-based) 맞춤형 실습 교육 시스템 구축
- EdgeChipLab 공식 수료 인증서(Certificate of Completion) 발행: 각 레벨별 실기 기술 평가 검증 통과 시 연구소 명의의 인증서 부여 및 글로벌 반도체 기업 채용 및 진학 시 기술 역량 증빙 활용
▶ Amazon Bestsellers (Author: Roger Kim)
- AI NPU System Design with Python and Verilog (2026) – #2 Bestseller in Digital
- Semiconductor School (2022) – #1 New Release in Semiconductor
▶ FPGA 기반 쿼드코어 NPU 설계 논문 공식 게재 (IJIBC/KCI 등재지)
- FPGA Implementation of a Deterministic and Bit-Accurate Quad-Core Quad-Cycle Systolic Ensemble NPU for Edge Inference (2026)
- 쿼드코어 시스톨릭 NPU 아키텍처의 학술적 검증 및 실증 완료
▶ 실전형 Vision/ISP 실물 하드웨어 및 파이프라인 가속기 구현
- CMOS 센서 수신 제어망: OV7670 초기화 커널 및 가상 VGA 샘플러 구현 완결
- 듀얼 포트 BRAM 프레임 버퍼: 비동기 클럭 도메인 간 메타스테이빌리티(Metastability) 근본 차단
- SSD1331 OLED 드라이버: 연속 프레임 갱신 제어 유닛 기반의 고속 디스플레이 인터페이스 검증
- 4-Mode 픽셀 처리 가속기: 싱크 버퍼 및 포화 연산 구조를 적용한 실시간 하드웨어 가속
▶ [Silicon Verification]고신뢰성 Edge AI 실시간 추론 및 자동 추적 시스템 실장 구현
아래 사진은 외부 IP나 소프트웨어 가속의 개입없이, Verilog RTL만으로 이미지 센서 입력을 실시간 NPU 추론 및 OLED 디스플레이에 결과를 출력하는 모든 과정을 보급형 Arty-S7 FPGA에 USB 전원만으로 저전력 동작 구현한 내용입니다.
* 실시간 하드웨어 Dynamic ROI Tracker (자동 추적 시스템): 카메라에서 유입되는 고속 이미지 픽셀 스트림을 실시간 프루빙합니다. 디지털 이미지 숫자가 존재하는 타겟에 대해서 붉은색 가이드 박스는 타겟을 캐치하고자 자동 트래킹으로 이동하여 박스내에 목표를 정렬합니다. 이때 사용한 기술은 Dynamic ROI Tracker, Zero-DSP / Division-Free 고효율 연산 기법, Multi-objective FOV Blinders (멀티 오브젝트 간섭 차단), Dynamic Spatial Translation (숫자 이미지 추론 정렬), CDC(Clock Domain Crossing) 메타스테이빌리티 방어 입니다.* 숫자 이미지 추론: 카메라에 촬영된 손글씨 숫자는 파이썬(Python)과 100% Bit-True 연산 무결성이 증명된 NPU에 인입되어 추론되며, 목표에 대한 추론결과는 보드에 장착된 OLED 우측 상단의 녹색 숫자(아래 사진의예: 5, 7, 1, 4)로 결과를 출력합니다.* Value Proposition: 본 실장 데모는 "수강생이 직접 설계한 Verilog 코드가 어떻게 실제 실리콘 하드웨어로 변환되고, 현실 세계의 카메라 영상을 인식하며 목표를 추적/이동하면서 자동 정렬을 진행하여 오차 없이 추론해 내는가"를 이해하는 이정표가 될 수 있습니다. 이것이 가능한 근본적인 원동력은 EdgeChipLab이 RISC-V CPU, AI NPU, 그리고 모든 핵심 ISP 주변장치 IP를 자체 개발하여 보유하고 있기 때문입니다. 수강생들은 외부 라이선스 제약이 없는 투명한 화이트박스 인프라를 바탕으로, 체계적인 온라인 강좌를 통해 공간의 제약 없이 집에서 전체 SoC 아키텍처를 마음껏 수정하고 확장하며 실무 노하우를 본인의 지식으로 내재화할 수 있는 실전적 현장 중심의 교육 체계라 자부합니다. 보드 실장 검증은 수강생이 보유한 보드를 사용하거나, 보드가 없는 경우 EdgeChipLab 강남교육장에서 현장 실습을 진행할 수 있습니다.

▶ [Silicon Verification] AURA-Edge SoC 기반 실시간 지능형 센서 융합 플랫폼 구현
AURA-Edge는 자체 설계한 표준 5-Stage Pipeline 기반 RV32I 32-bit RISC-V 프로세서를 중심으로, GPS, AI NPU, Camera, OLED 및 각종 센서 인터페이스를 통합한 FPGA 기반 Complete Edge SoC Platform입니다.
외부 운영체제나 상용 프로세서 IP 없이, 독자 설계한 CPU 위에서 Bare-Metal C 프로그램이 직접 실행되며 실시간 센서 데이터를 처리합니다.
본 시스템은 경량 보급형 FPGA인 Arty S7-25 상에서 구동되며, 실제 실리콘 환경에서 다음 기능의 통합 동작을 검증하였습니다.
Verification Highlights
- 표준 5-Stage Pipeline RV32I 프로세서 FPGA 실장 검증
- Bare-Metal C Firmware 실행
- MMIO 기반 주변장치 제어
- GPS(NMEA) 실시간 파싱
- Geo-fencing 엔진 구현
- AI NPU 인터페이스 검증
- UART 기반 시스템 로그 출력
- CPU–GPS–NPU–Firmware 전체 데이터 경로 검증
실제 시스템은 아래와 같은 형태로 동작합니다.
GPS Module→ NMEA Stream Reception→ AURA-Edge RV32I Processor→ Geo-fencing Engine→ AI NPU Accelerator→ UART / OLED Output
Value Proposition: 본 FPGA 구현은 단순한 CPU 동작 확인이나 테스트 프로그램 실행 수준을 넘어, 자체 설계한 프로세서가 실제 응용 소프트웨어를 구동하며 외부 센서와 AI 가속기를 통합 제어하는 Complete Edge SoC Platform임을 입증합니다.
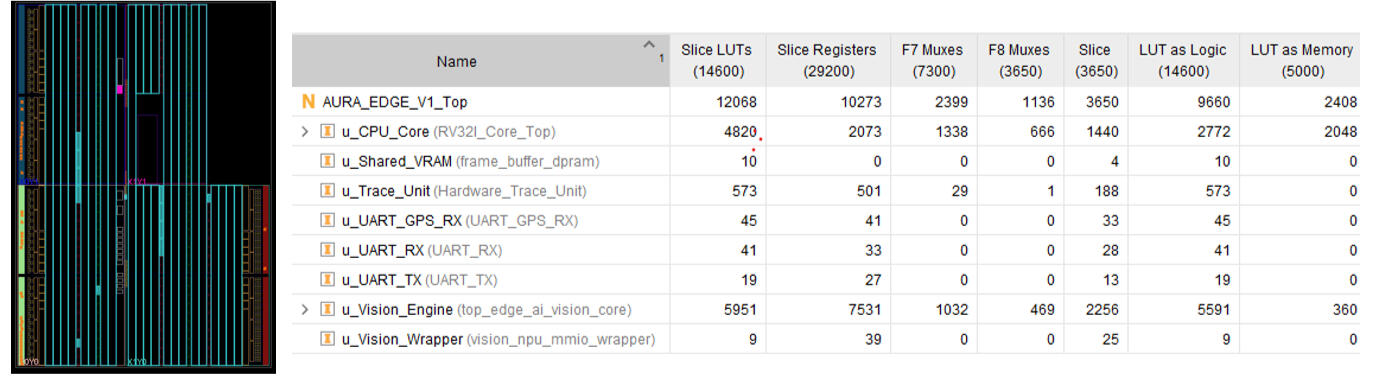

▶ [Silicon Verification] AURA-Edge Transformer Attention Engine 구현
[End-to-End Single-Head Self-Attention with FPGA Verification]
AURA-Edge SoC V2.0은 RV32I 프로세서와 CNN 기반 NPU를 재구성하여 Transformer Attention 연산을 수행하는 이기종(Heterogeneous) HW/SW Co-Design 구조를 구현하였습니다. 선형 대수 연산(Q, K, V 생성)은 NPU의 공간 병렬성(Spatial Parallelism)을 활용하여 가속하고, Softmax 및 Context Vector 생성은 RV32I 펌웨어가 담당합니다. 이를 통해 추가 MAC Array 없이 Single-Head Self-Attention 파이프라인을 구현하였습니다.
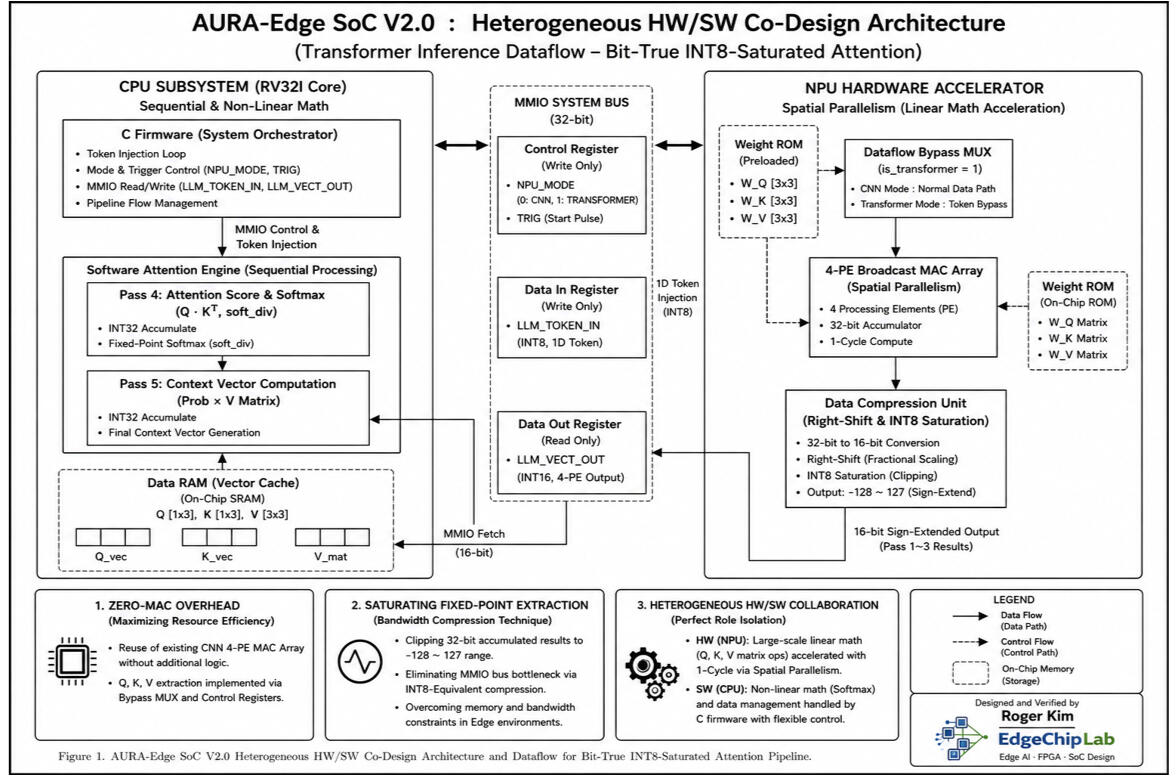
[100% Bit-True FPGA Verification]
동일한 입력 토큰에 대해 Vivado RTL 시뮬레이션과 실제 Arty S7 FPGA 실측 결과를 비교한 화면입니다. Q, K, V 벡터, Attention Score, Softmax Probability, Context Vector가 모두 동일하게 출력됨을 확인하였습니다. 이를 통해 Python Reference Model → Verilog RTL → FPGA Hardware에 이르는 전체 데이터 경로의 연산 무결성을 검증하였습니다.
▶ AMBA AXI Interface Full-Stack 교육 모듈 완비
AXI Learning Example (Phase 1 ~ Phase 6) 설계 및 검증 패키지 구축 완료
- Phase 1 (Single Write): CPU Master FSM 및 BRAM Slave FSM 기반 단일 쓰기 트랜젝션 구현 및 VALID/READY 핸드셰이크 제어 유닛 완비
- Phase 2 ~ 5 (Advanced Channels): Single Read, Write Burst, Read Burst, 복합 트랜젝션 처리 최적화
- Phase 6 (System Expansion): Multi-Master 환경 지원을 위한 Interconnect, 중재기(Arbiter) 회로 및 Address Decoder 확장 설계 인프라 확보
- Verification Infra: Vivado 시뮬레이션을 로그(Pass/Fail)를 통한 검증 확인
▶ NPU Achieved (Vol. 1 & 2): MNIST & CIFAR-10 추론 NPU 설계 완료. Python reference와 Verilog RTL 간의 Bit-True Accuracy 구현 및 Quad-Core Quad-Cycle Systolic NPU FPGA 하드웨어 동작 실장 완료
- Open Source Contribution (Technical Transparency): NPU System Design Volume1
- Key Features: Volume 1(Arty S7) MNIST 추론 프로젝트의 Verilog-HDL RTL 소스 코드 및 Python Reference 모델 공개. 100% Bit-True Verification을 위한 검증 환경(Testbench) 포함
[In Progress (Vol. 3 & Beyond)]: SoC 통합형 프로그래머블 플랫폼 및 CIFAR-100 인식을 위한 고성능 추론 엔진 개발 중
▶ RISC-V SoC Design Portfolio & Silicon Verification
1. TinyRV32I 경량 SoC 개발완료 (입문 플랫폼):
RISC-V RV32I Subset 기반 32-bit 경량 CPU 및 표준 5-Stage 파이프라인 구조 설계. Board I/O, SONAR, CAMERA, NPU, OLED, STEP MOTOR를 아우르는 MMIO 인터페이스 완비 및 Bottom-up 방식 RTL 구현 검증
2. 표준 5-Stage Pipeline 기반 RV32I 32-bit RISC-V 프로세서 및 비전/NPU 통합 SoC (Main 플랫폼):
- Advanced Architecture: 표준 RV32I Base Integer Instruction Set(40개 명령어 전면 해독) 설계 및 하드웨어 해저드 통제망(Forwarding & Interlock Unit) 구축
- Global Compliance Pass: RISC-V 국제 재단 공식 컴플라이언스 프레임워크(ACT) 100% Pass 완료 (2026년 5월)및 Arty S7-25 FPGA 실장 동작
- System Integration: GCC 기반 Bare-metal C 실행 및 Timer/Interrupt 기반 임베디드 시스템 아키텍처 고도화, NPU 가속기 전용 고속 협업 채널 및 디버그 모듈 탑재
- Future Scalability: 미래 다중 코어 확장을 위한 '표준 버스 훅' 개방을 통한 SMP-Ready 아키텍처 및 FreeRTOS 호환 인프라 정의
*RISC-V ACT 결과는 RISC-V Arch-Test Maintainer인 David Harris 교수와 공개적으로 공유되었으며, 공식 Arch-Test 저장소에서 검토 의견을 받았습니다.
SECTION 04. FULL-STACK CURRICULUM
▶ 설계·실장구현·검증을 아우르는 차별화된 반도체 기술 커리큘럼
EdgeChipLab은 상용 CPU와 블랙박스 자산을 단순히 가져다 쓰는 기존 임베디드 교육과 다릅니다. 트랜지스터 계층부터 자체 코어 설계, 운영체제 이식, 멀티코어 아키텍처 확장까지 전체 시스템 스택(Full-Stack)을 수강생이 직접 통제하고 빌드하는 실장 동작 구현 인프라를 제시하며 완성합니다.Level 1. 독자 설계 RV32I 프로세서 시스템 (프로세서 기초)
- 5-Stage RV32I 프로세서 설계 및 FPGA 구현
- RISC-V ACT(Architectural Compliance Test) 검증
- EdgeScope™ 기반 사이클 정밀 파이프라인 추적
- UART, 7-Segment, OLED, 초음파 센서, CMOS 카메라 인터페이스 구현
- 자체 설계 CPU에서 Bare-Metal C 프로그램 실행
- 구현 결과물: FPGA 실증 완료 RV32I 프로세서 플랫폼Level 2. Interrupt-Based Embedded System (예측 가능 시스템 기초)
- 하드웨어 타이머 인터럽트 설계
- CSR(Control and Status Register) 구현
- 예외(Exception) 및 트랩(Trap) 처리 구조 설계
- Polling 기반 제어에서 Interrupt-Driven 구조로 전환
- 결정론적 이벤트 처리 및 응답 시간 분석
- 구현 결과물: 인터럽트 기반 실시간 제어 플랫폼Level 3. RTOS 기반 임베디드 시스템
- FreeRTOS 커널 포팅
- 태스크 스케줄링 및 문맥 전환(Context Switch)
- 센서 및 디스플레이의 독립 주기 제어
- 실시간 멀티태스킹 소프트웨어 구조 구현
- 하드웨어 성능 모니터(HPM)를 활용한 시스템 프로파일링
- 구현 결과물: RTOS 기반 RISC-V 플랫폼Level 4. 멀티코어 확장 아키텍처 (병렬 처리 시스템 구현)
- Dual-Core 및 Quad-Core RV32I 아키텍처 확장
- 공유 메모리(Shared BRAM) 설계
- 코어간 통신 및 동기화 메커니즘 구현
- Mutex, Semaphore, Atomic 연산 지원
- 병렬 처리 및 작업 분산 기법 학습
- 구현 결과물: FPGA 기반 멀티코어 RISC-V 시스템Level 5. AI 가속기 및 NPU 설계 (AI 추론 AI H/W 구현)
- CNN 기반 신경망 구조 이해
- 시스톨릭(Systolic) 처리 구조 설계
- 정수 기반(Quantized) 추론 엔진 구현
- 하드웨어-소프트웨어 협업(Co-Design) 방법론 학습
- FPGA 기반 실시간 이미지 분류 실습
- 구현 결과물: 독자 설계 AI 추론 가속기(NPU)Level 6. AI 임베디드 SoC 통합 (지능형 비전 시스템 구현)
- 멀티코어 RISC-V CPU 클러스터 구성
- Quad-Core 시스톨릭 NPU 통합
- 카메라 입력부터 추론까지의 전체 데이터 경로 설계
- 프레임 버퍼 및 CDC(Clock Domain Crossing) 구조 구현
- GPS 및 센서 융합 Fusion 시스템 구성
- OLED 및 디스플레이 출력 연동
- 구현 결과물: FPGA 기반 AI Edge SoC 플랫폼 (AURA-Edge)
AURA-Edge 시스템은 카메라 영상을 NPU로 가속해 차량 번호판을 실시간 인식하고, 이를 해시 알고리즘으로 파싱된 GPS 지명 데이터와 융합합니다. "어디에서 어떤 차량이 포착되었는지"를 OLED로 즉각 출력하는 독립형 스마트 관제 Edge SoC입니다. FPGA로 직접 구현하여 확인합니다.Level 7. 고신뢰성 검증 및 투시형 컴퓨팅
(Glass-Box Verification Ecosystem)
- Cycle-Accurate 파이프라인 추적
- Hazard, Stall, Flush 시각화
- Hardware Performance Monitor(HPM) 기반 계측
- 결정론적 실행(Deterministic Execution) 검증
- 회귀 검증(Regression Test) 및 Compliance 검증
- 연구용 투시형 검증 플랫폼 구축
- 구현 결과물: 추적 가능한 신뢰성 컴퓨팅 플랫폼Level 8. 지능형 무선 관제 및 비동기 원격 제어 (Intelligent Wireless Monitoring & Remote Control)
- 스마트폰 UI 기반 하드웨어 파라미터 실시간 양방향 제어
- 무선 관제 시스템 구축
- 구현 결과물: 무선 제어 기반 지능형 엣지 대시보드 (AURA-Remote Dashboard)용 SoC 구현
- 시스템 아키텍처 개요: AURA-Remote Dashboard는 초경량 비동기식 원격 관제 플랫폼입니다. NPU 프론트엔드 버퍼에서 추출된 핵심 특징점만을 텍스트 패킷으로 압축하여 WiFi 통신 모듈(ESP32)을 통해 전송합니다. 사용자는 스마트폰 브라우저를 통해 엣지 하드웨어가 바라보는 시각(추론 타겟)을 데이터 지연 없이 흑백 텐서 형태로 확인하며, 외부 환경 변화(조도, 노이즈)에 대응하여 NPU 전처리기 임계값(Threshold) 등 카메라 RTL의 레지스터 값을 원격 튜닝할 수 있는 진정한 IoT-SoC 융합 에코시스템을 완성합니다.Level 9. Transformer 추론엔진 설계 및 FPGA구현
- Transformer 아키텍처 이해
- Self-Attention 메커니즘 구현
- Q(Query), K(Key), V(Value) 벡터 생성 구조 설계
- Fixed-Point Softmax 연산 구현
- Context Vector 생성 및 Bit-True 검증
- Hardware/Software Co-Design 기반 Transformer 추론 엔진 설계
- CNN PE 재활용(Dataflow Reuse) 기법 학습
- FPGA 기반 Transformer Attention 실증
- Modern LLM의 핵심 연산 원리 학습
- 구현 결과물: AURA-Edge Transformer Engine (AURA-TR)
- 시스템 아키텍처 개요: AURA-TR은 기존 CNN 추론용 시스톨릭 어레이를 재활용하여 Transformer의 Self-Attention 연산을 수행하는 경량 AI 추론 엔진입니다. NPU 하드웨어는 Query, Key, Value 벡터를 실시간 생성하며, RV32I 프로세서는 Softmax 및 Context Vector 계산을 수행하는 이기종(Heterogeneous) HW/SW 협업 구조를 구현합니다.
특히 Python 참조 모델, C 펌웨어, Verilog RTL, FPGA 실측 결과가 모두 100% Bit-True로 일치함을 검증하여, 알고리즘부터 실리콘까지의 완전한 검증 체계를 제공합니다.
최종적으로 학습된 Transformer 모델이 실제 FPGA 상에서 추론을 수행하고, 사용자는 Self-Attention 내부 데이터(Q, K, V, Score, Probability, Context)를 실시간으로 관찰할 수 있는 Glass-Box AI 플랫폼을 구축합니다.
▶ EdgeChipLab 강남 전용 연구소 및 교육장 인프라 확보



실증 중심의 엘리트 반도체 설계 인재 양성을 위하여, 교통과 접근성이 뛰어난 서울 강남(역삼동) 소재의 전용 연구소 및 하드웨어 교육장 인프라를 확보하였습니다. 본 공간은 이론 강의 위주의 교육에서 더 나아가, Semiconductor School에서 제공하는 소스코드로 수강생들이 직접 설계한 RISC-V CPU 코어 및 최첨단 NPU 아키텍처 Verilog RTL 자산을 FPGA 보드에 실장 검증 할 수 있는 엣지 컴퓨팅 하드웨어 실습 인프라를 구비하고 있습니다.글로벌 반도체 산업 현장 경험과 학술적 전문성을 바탕으로, 본 강남 인프라에서 1:1 전문 멘토링 및 하드웨어 bottom-up 구현 실무가 집중적으로 전개됩니다. 이론적 수식과 가상 시뮬레이션 파형을 넘어, 실물 실리콘 인프라 레벨에서 시스템 무결성을 눈으로 직접 검증하고 완성하는 EdgeChipLab 교육 철학의 핵심 기지입니다.
SECTION 05. GLOBAL STRATEGY
▶ Global Talent Incubation
아마존 플랫폼 모델을 기반으로 글로벌 지식 보급을 선점하고, 반도체 1위 주역 해외 주재원 실무 경험을 갖춘 전문가 집단의 정교한 교육과 멘토링을 통해 글로벌 우수 엔지니어를 양성합니다. 전 세계 엔지니어가 기술적으로 결집하는 디지털 실습 플랫폼 및 지식 오픈 마켓 생태계(by EdgeChipLab)를 구축하여 글로벌 반도체 설계의 표준을 제시합니다.
▶ 강사 초빙 및 오픈 생태계 확장
EdgeChipLab은 반도체 지식의 전문성을 극대화하기 위해 강사진 및 현업 아키텍트들의 참여를 환영합니다. 반도체 공정/소자, 디지털/아날로그 설계, 메모리/S.LSI 제품, 설계/검증 방법론, 임베디드 소프트웨어, AI 가속기, 반도체 마케팅 등 반도체 전 분야에서 전문 지식을 보유하신 분께서는 본인의 강의 컨텐츠를 Semiconductor School 플랫폼에 자유롭게 개설(Amazon모델)하실 수 있습니다.특히, 참여하시는 강사진은 EdgeChipLab 강남 연구소에서 수강생 대상의 기술 컨설팅, 오프라인 멘토링, 그리고 반도체 기업 입사 자문 등의 컨설팅 활동을 수행하실 수 있습니다.EdgeChipLab의 실물 FPGA 하드웨어 인프라와 글로벌 플랫폼 모델을 공유하여 기술적·학술적 시너지를 창출하고, 최고 수준의 반도체 교육 및 엔지니어링 컨설팅 생태계를 함께 선도해 나갈 분들을 초빙합니다.강의 개설 및 컨설팅 파트너십 문의: [email protected]
회사명: EdgeChipLab
주소: 서울특별시 강남구 도곡로3길 13, 르메이에르타운 203-3호
연락처: [email protected]
Copyright © 2026 EdgeChipLab. All rights reserved.